Preamble
This is more or less my thoughts about how to structure a bulk loader for chado.
Majority of the ideas come from writing obo2chado loader. obo2chado still lack the design that
i am aiming now, but most of the upcoming one will follow that. And the future idea is to refactor the obo loader to that mold.
Design
Scope and expectation
- The input would be some sort of flat file.
- The data will be loaded to a relational backend. It could definitely be generalized, but at this moment it is not considered.
Reading data
There should be an object oriented interface for reading data from flat files. That object is expected to be passed
along to other classes. For example, for obo2chado loader i have used the ONTO-Perl module.
Database interaction
Probably one of the import one. It’s better to have an ORM that supports mutiple backends and bulk loading support. For Perl
code, i have used BCS a DBIx::Class class layer for chado database.
Loading in the staging area
This part is supposed to get data from flat file to temp tables of RDBMS. To start with, lets assign a class which
will manage everything related to this task. First lets figure out what kind of information the class needs in order to perform those tasks.
For the sake of understaing we name it as StagingManager ….
Staging manager
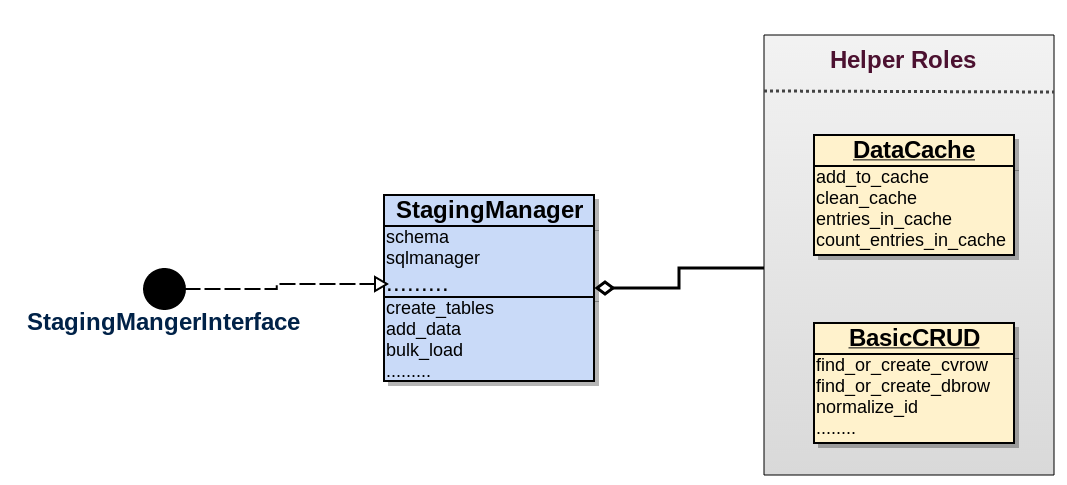
Attributes
- schema: Should have an instance of
Bio::Chado::Schema. A ORM/Database object for all database centric tasks. If its an ORM, then it should better provide access to some bulk mode operation or at least low level objects for bulk support. - chunk_threshold: I kind of thrown this in, it will be used for bulk loading in chunk.
- sqlmanager: Should have an instance of
SQL::Lib. A class that manages handling of sql statements. I found it easy to manage instead of inlining it in the class itself. With growing sql statments, it could become cumbersome to navigate through code. Provides better separation between code and non-code content. Forobo2chado, i have used SQL::Library module, seems to be a very good choice. - logger: An instance of an logger.
Methods
- create_tables: Create temporary tables.
- create_indexes: Create indexes/constraints in temp tables as necessary.
- drop_tables: Drop temp tables if necessary(probably not needed).
- bulk_load: Load data in those temp tables, should be in bulk mode. If there are multiple data sections going to different temp tables and they are independent then loading could be parallalized. This method is expected to be backend specific, so for example for postgresql backend, we used COPY command to load the data.
- add_data: This would be more or less to add a row of
data_objectto the manager. It will cache the data unless it is above threshold andload_datais invoked.
1 2 3 4 5 6 7 8 | |
Remember, there will be a separate manager class for each backend. However, they should share a identical interface.
And then the common attributes and methods are then put into an interface role which any staging loader have to consume and implement.
Helpers
In addition, we also need some helper classes that could have the following responsibilities:
- Managing data caches: It could be any implementation that provides a temporary storage. So, far i have used a simple in memory array for
ob2chadoloader. It is implemented as a parametric Moose Role. Consume that role in a Moose class..
1 2 3 4 | |
The above will import four methods/element making a total of 8 methods in the class. For term it will import …
1 2 3 4 | |
The use will be very simple…
1 2 3 4 5 | |
- Basic CRUD for database: It is absolutely chado specific pattern where four tables cv,cvterm, dbxref and db are frequently reused. Here is one of the implementation. It provides bunch of reusable methods that mostly works on one of the four tables mentioned earlier…
1 2 3 | |
- Data transformations: There are few methods needed here and there, however currently they are private to the other helpers. Still nothing there which stands out.
However, these are not set in stone and there could be handful of helper classes. And it depends on the manager class which one it needs to consume. But its important to share the helper classes for different backend specific manager class. So, all the helper classes should have a defined interface.
Loading into chado from staging
Quite obviously, the responsible entity(or class) will transfer the data to the actual tables in chado database. Lets get down to the interface ….
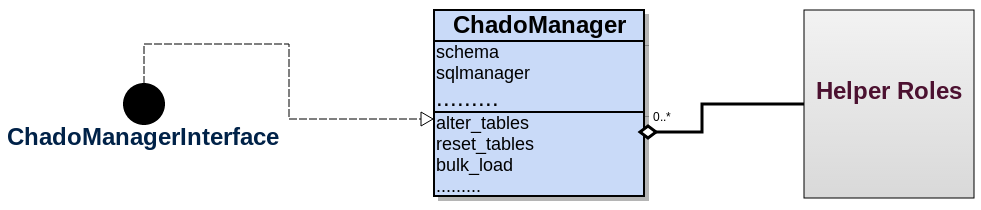
Attributes
- schema: Mentioned earlier.
- sqlmanager: Similarly, mentioned earlier.
Methods
- alter_tables: To prepare chado tables for bulk load, such as disabling indexes and/or foreign keys etc, if needed.
- bulk_load: This method generally runs a series of all sql statements to do the actual data loading.
- reset_tables: Should reset the chado tables to its pristine states if the “alter_tables“` method did any change. Also any other procedure.
- logger: An instance of an logger.
The methods should run in the following order …
1 2 3 | |
This loading phase should run after the staging as it needs data from staging tables. As usual, the methods and attributes should be wrapped around a generic interface role.
The loader itself
The loader would be provide a command line/webapp interface that basically coordinate these managers(both staging and chado) to load it. The loader frontend also ensures that all the steps are executed in order. Here’s how the software stack interacts with each other.
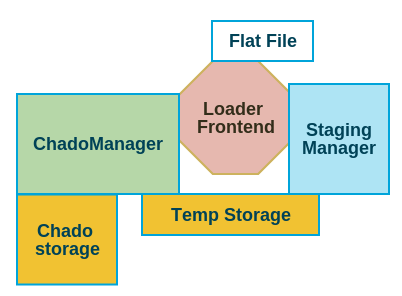
- The loader frontend only has direct interaction with the flat file, however it does not have any connection with storage backend. It does also interacts with both the managers.
- Staging manager interacts with only temp storage whereas Chado manager interacts with both storages. However, the managers are completely decoupled.
The diagram below shows data flow where it goes from the flat file to the chado database.
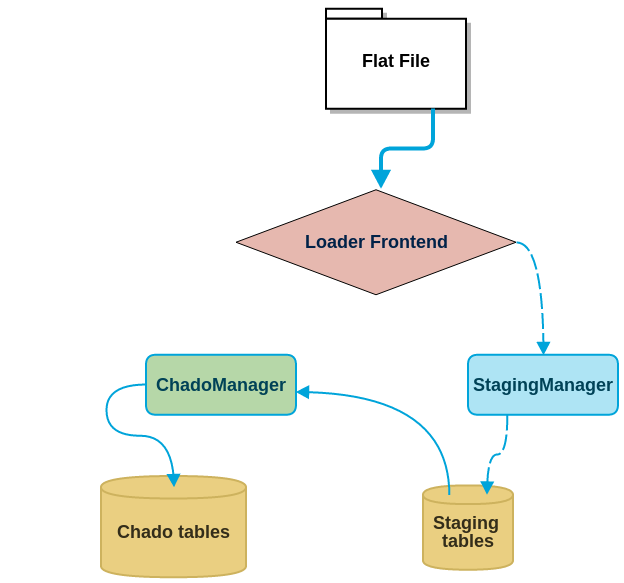
- The data get pushed by the frontend to the
Stagingmanagerand then into staging tables. - The
Chadomanagerthen pulls it from staging table and push it to the chado database.
For an implementation of this pattern look at perl based oboclosoure2chado
command.